电子产品世界
威廉希尔 官网app
EEPW观点
电源与新能源
光电显示
论坛
博客
威廉希尔中文网站
威廉希尔 官网app
电源与新能源
光电显示
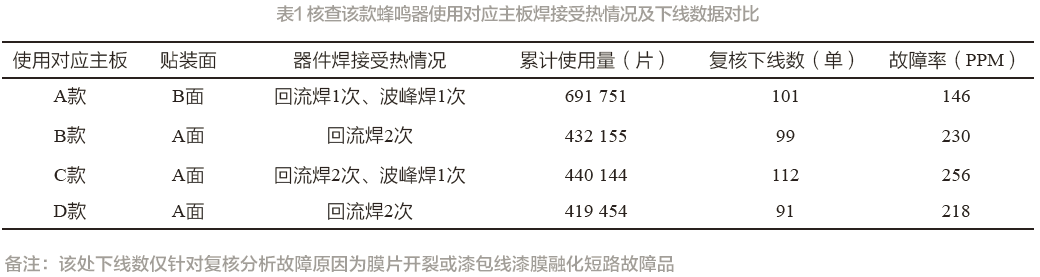
贴片蜂鸣器功能可靠性研究
2022-08-14
2022我国电子信息产业规划重点有哪些?CITE一展尽览
2022-08-12
浅析NFT在知识产权领域的司法实践以及法律风险
2022-08-12
基于亿智SA206 DMS的AI智能车载终端解决方案
2022-08-12
基于 Microchip PIC16F1779 onsemi NCV78343 和 OSRAM LED 的 CAN/LIN 通讯矩阵式大灯方案
2022-08-12
2022-08-12
海光成功上市 未来大有可期!
2022-08-12
自动化人工智能对技术创新者至关重要
2022-08-12
有源相控阵与无源相控阵雷达
2022-08-12
芯亮相| 酷芯携全栈智能无人机芯片及解决方案参展2022深圳无人机大会
2022-08-12
一文了解数藏行业全貌,这份《数字藏品应用参考》请收好
2022-08-12
安森美庆祝在新罕布什尔州扩张碳化硅工厂
2022-08-12
区块链司法应用的发展路径
2022-08-12
区块链和加密货币可以单独共存吗?
2022-08-12
区块链意味着我们已经过了“基金顶峰”
2022-08-12
点击查看更多
电子设计方案
东为 DW232Y指纹识别串口电路模块设计
2022-07-08
控制电路
外接通信
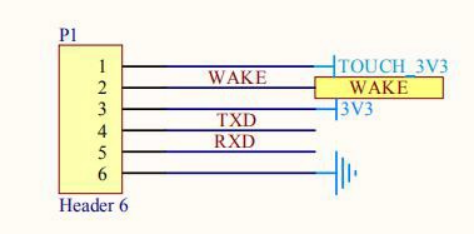
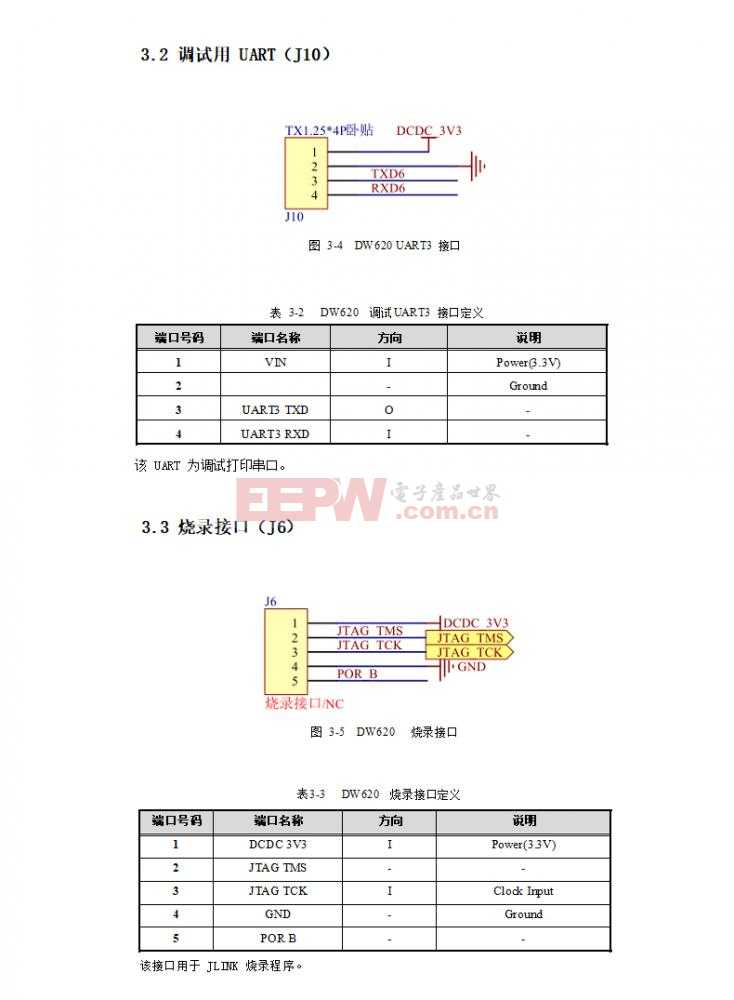
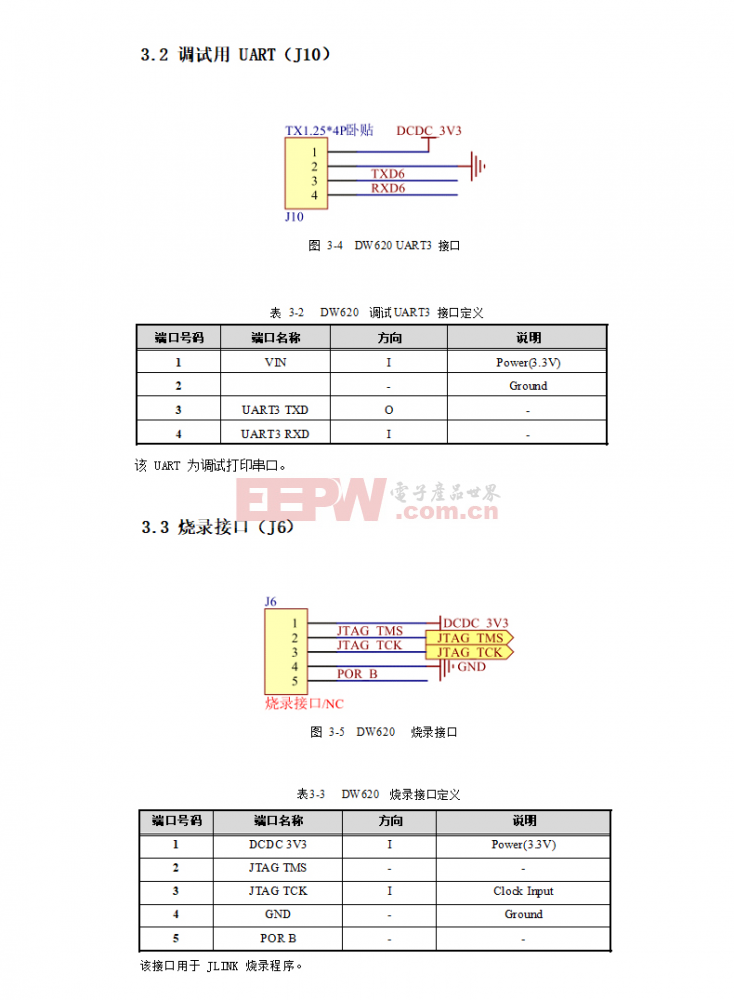
东为 DW620人脸识别模块接口电路设计
2022-07-08
接口电路
控制电路
优库 DW232Y指纹模块接口电路图
2022-07-08
接口电路
控制电路
优库 DW620人脸识别模块接口电路图
2022-07-08
接口电路
控制电路
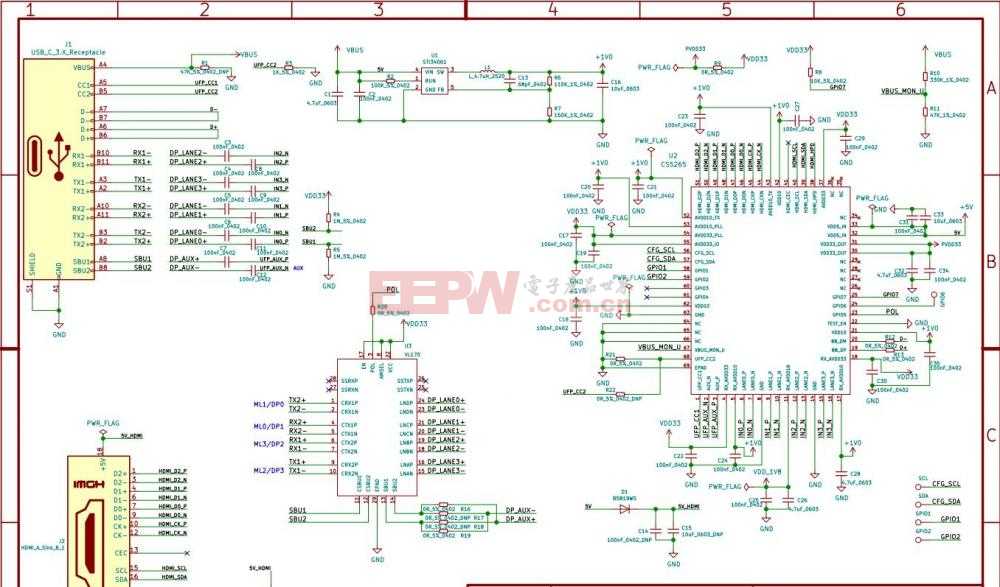
TypeC母座正反插转HDMI扩展投屏方案芯片CS5265+VL170设计参考电路
2022-05-13
CS5265母座正反插
typec扩展
投屏方案
白皮书
通过自动插入过孔减少 IR 和 EM 问题
上传时间:2021-11-01
文件类型: PDF
文件大小: 578.62K
使用电阻和电流密度数据调试 P2P 结果
上传时间:2021-11-01
文件类型: PDF
文件大小: 890.95K
IC中的高级电气规则检查
上传时间:2021-11-01
文件类型: PDF
文件大小: 670.27K
半导体设备控制附加软件介绍文档下载(内含影片)
上传时间:2021-09-09
文件类型: PDF
文件大小: 754.93K
Quick and Easy Tips for Solving EMI Issues(解决 EMI 问题的快速简便技巧)
上传时间:2021-08-25
文件类型: PDF
文件大小: 954.83K
可配置且简单易用的组合式可靠性检查
上传时间:2021-03-31
文件类型: PDF
文件大小: 1280.95K
MENTOR、AMD 和 MICROSOFT 合作开展云上 EDA
上传时间:2021-03-31
文件类型: PDF
文件大小: 571.97K
颠覆性的半导体测试方法
上传时间:2021-02-03
文件类型: PDF
文件大小: 10589.92K
CMP 建模的机器学习方法
上传时间:2021-01-20
文件类型: PDF
文件大小: 1902.86K
树莓派杂志《The MagPi》第101期(英语原版)
上传时间:2021-01-11
文件类型: PDF
文件大小: 32791.44K