HBM,爆炸式增长
高带宽内存(HBM)是下一代 DRAM(动态随机存取存储器)技术,可实现超高速和宽数据传输。
HBM 的核心创新在于其独特的 3D 堆叠结构,其中多个 DRAM 芯片(4 层、8 层甚至 12 层)使用先进的封装技术垂直堆叠。3D 结构使 HBM 能够以比 GDDR 等传统内存解决方案高得多的带宽(数据传输速率)运行。
可以这样想:HBM 不是将所有内存芯片并排布置在平板上,而是将它们像多层建筑一样堆叠起来。这种垂直集成与复杂的电气连接相结合,为数据创造了一条高速公路,从而能够更快、更高效地与处理器进行通信。
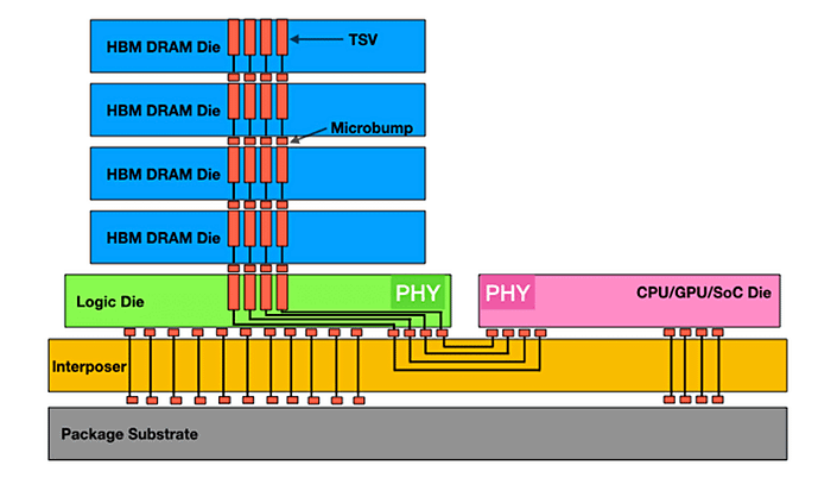
HBM 3D 结构(来源:Semiconductor Engineering)
为什么高带宽内存(HBM)对 AI 至关重要?
根据 IDTechEx 的报告,全球 HBM 市场将在未来十年内增长 15 倍。这种爆炸式增长的核心在于高带宽内存(HBM)以超高带宽和低延迟为图形处理单元(GPU)提供海量数据流的独特能力。
GPU 与中央处理器
CPU(中央处理器)托管少数针对顺序、逻辑复杂的任务进行了优化的复杂内核,而 GPU 则拥有数千个旨在并行处理数据的简单内核。每个 CPU 核心都具有强大的单线程性能和复杂的控制逻辑。然而,现代 AI 训练和推理涉及处理数 TB 的参数和中间激活,远远超出了几个 CPU 内核可以有效处理的范围。
GPU 专为图形渲染和视频编码而设计,因此它们可以同时或并行处理大量相对简单的计算。这种大规模并行架构使 GPU 成为 AI 训练和推理的完美之选,这涉及以相对规则的计算模式(一次进行数百万次乘加运算)处理大量数据集。这就是为什么 GPU 成为 AI 加速器的核心芯片。
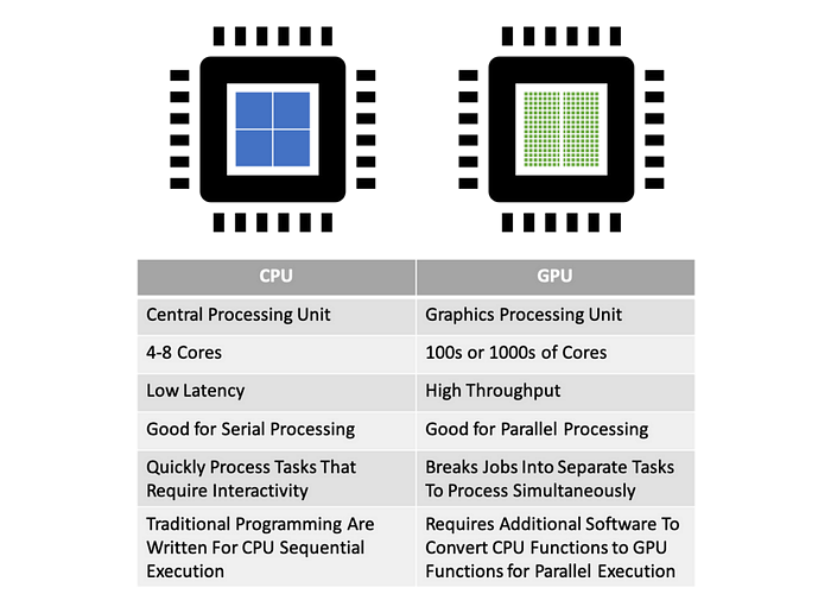 CPU 与 GPU 的比较(来源:Layerstack)
CPU 与 GPU 的比较(来源:Layerstack)
内存带宽决定 GPU 速度
内存带宽是指内存子系统每单位时间(通常为每秒)可以传输的数据总量。它直接测量处理器(如 CPU 或 GPU)从连接的内存(DRAM)读取数据或将结果写入其的速度。
例如,如果内存系统每秒可以可靠地传输 100GB 的数据,则其带宽为 100GB/s。您可以使用以下公式粗略估计带宽:
内存带宽(GB/s)= [总线宽度(位)× 有效传输速率(GT/s) ] ÷ 8
Bus Width (bit)(总线宽度(位)):内存接口一次可以并行传输多少位数据。更宽的公交车就像在数据高速公路上拥有更多的车道。例如,HBM2E 的接口宽度可以达到 1024 位或更高,远远超过 GDDR6 的 32 位。
有效传输速率(Hz / GT/s):每秒数据传输作数。现代高速内存(如 GDDR、HBM)通常使用双倍数据速率(DDR)或四倍数据速率(QDR)技术,在时钟信号的上升沿和下降沿传输数据。
为了实现更高的内存带宽,您需要高有效传输速率(数据「运行速度快」)和宽总线宽度(许多「数据通道」)。
为什么 HBM 的 Ultra-Wide Bus 解决了内存瓶颈
在 AI 应用程序中,模型的参数可能为数百 GB 甚至 TB。在计算过程中,GPU 经常与内存交换大量参数和中间结果(激活、梯度)。
传统系统将内存分层到缓存(SRAM)→主内存(DRAM)→存储(SSD/HDD)中,但由于内存壁问题和处理器利用率不足,当今的 AI 和 HPC 工作负载暴露了这种层次结构的限制。为了防止强大的 GPU 受到数据供应的瓶颈(即避免「饥饿」的 GPU),该行业正在重新划分内存堆栈:
封装内 HBM:共同封装的 3D 堆叠 DRAM 距离 GPU 芯片仅几英寸。
CXL 池内存:跨加速器共享 DDR 池。
基于 NAND 的内存:SLC 优化存储和 TLC/QLC,适用于较冷的数据层。
高带宽内存(HBM)具有更高的吞吐量,可以同时处理来自各个内核的多个内存请求。例如,HBM3E 通过结合高速接口技术,将其数据「高速公路」(总线宽度)大幅扩大到 1,024 甚至 2,048 位,从而使每个堆栈的速度达到 1,225 GB/s。
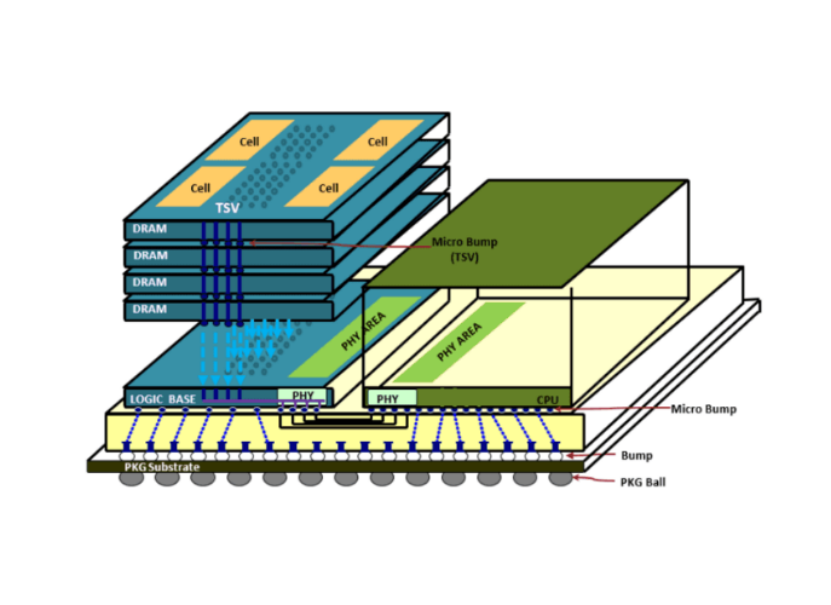
HBM 使用 3D 存储芯片阵列,垂直堆叠并使用硅通孔(TSV)并联连接。(来源: TOP500)
最新一代 HBM3E 使用带有微凸块和底部填充的热压缩来堆叠 DRAM 芯片,然而,SK 海力士、三星和美光等制造商正在过渡到更先进的封装技术,例如 HBM4 及更高版本的铜-铜混合键合,以增加输入/输出、降低功耗、改善散热、减小电极尺寸等。
视频随机存取存储器(VRAM)的作用
专为 GPU 设计的高速内存称为 VRAM(视频随机存取存储器)。在当今的高端 AI 和计算中,HBM 是占主导地位的 VRAM 解决方案。

VRAM 是 GPU 的专用内存缓冲区,用于存储关键数据以便快速访问。(来源: Ms.Code)
典型的显卡(或 AI 加速器)由一个 GPU 芯片与 VRAM 模块(通常是多个 HBM 堆栈)紧密耦合组成。
以下是 GPU 执行计算时的典型数据流:
数据加载:用于计算的初始数据通过 PCIe 等接口从速度较慢、较大的 CPU 系统内存(RAM)传输到 GPU 的专用高速 VRAM (HBM)。
并行计算:GPU 的众多计算内核从高速 VRAM (HBM)读取必要的数据段并执行密集的并行计算(例如,矩阵乘法、卷积)。
结果暂存:计算的中间或最终结果快速写回 VRAM (HBM)进行临时存储。
数据输出/保存:处理后的数据最终从 VRAM (HBM)传输回 CPU 系统内存(RAM)进行进一步处理或存储,或者在某些情况下(如图形输出),直接从 VRAM 输出到显示接口。
在图像识别、自然语言处理(NLP)和大型语言模型(LLM)训练/推理等 AI 任务中,模型涉及数十亿甚至数万亿个参数。计算在很大程度上依赖于 GPU 内核和 VRAM 之间持续、高速的数据交换。
因此,VRAM 的性能,尤其是其高速读写海量数据的能力,直接决定了 GPU 整体计算效率的上限。如果 GPU 核心急需的数据(指令、参数、中间结果)由于内存带宽不足或高延迟而无法按时交付,则计算单元将卡顿,浪费宝贵的计算能力并妨碍最佳性能(形成「内存墙」或内存瓶颈)。
这就是为什么 HBM 凭借其出色的高带宽(满足数据吞吐量需求)和低延迟(减少内核等待时间)已成为 NVIDIA H100 和 AMD MI300X 等高性能 AI 专用 GPU 不可替代的内存解决方案。
近距离观察 HBM:3D 结构
HBM 的核心创新在于其独特的「3D」结构。HBM 不是传统的平面存储芯片,而是像摩天大楼一样垂直堆叠多个标准 DRAM 芯片(称为 DRAM 芯片)。然后,这些芯片通过密集的硅通孔(TSV)在垂直方向上电气互连。
每个 DRAM 芯片都使用极薄的粘合剂材料进行粘合,最初通过微凸块在各层之间互连。
HBM 高性能的关键在于三个相互关联的核心技术要素:
堆栈:垂直堆叠多层 DRAM 芯片可实现单位面积存储容量的指数级增长(例如,8 层堆栈提供的容量是单个芯片的 8 倍),节省空间并实现更大的容量。
TSV(硅通孔):在堆叠的 DRAM 芯片内蚀刻小孔,并填充导电材料以形成垂直通道(直径仅为 5-10 微米)。这种高密度、短距离的垂直布线直接连接上下层的信号、电源和接地线,实现了传统平面布线无法实现的极宽总线宽度(超过 1024 位)。
中介层:一种精密的硅或有机衬底,可同时承载 GPU 芯片和 HBM 堆栈。它使用其表面和内部高密度布线(走线宽度/间距低至微米级)在极短的距离内将 HBM 堆栈的超宽接口与 GPU 芯片的高速 I/O 端口互连。
下图说明了 GDDR 和 HBM 之间的基本结构差异。
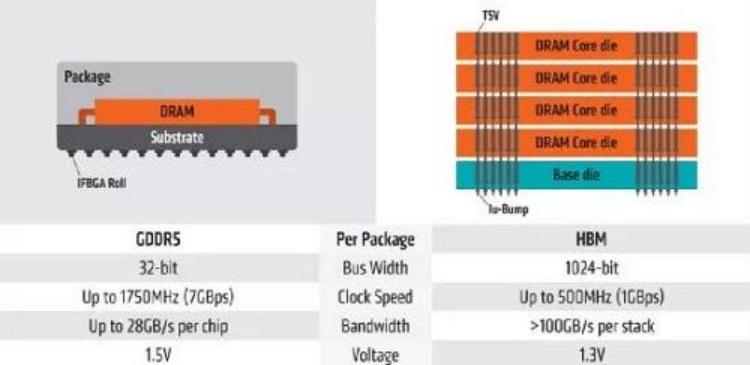 GDDR 和 HBM 的区别(来源: PC Perspective)
GDDR 和 HBM 的区别(来源: PC Perspective)
GDDR 的工作原理是什么?
多个独立的 DRAM 芯片(单个组件)在 BGA 封装中平面排列,并安装在 PCB 基板上的 GPU 芯片周围。
每个 DRAM 组件都需要独立、相对较长的 PCB 走线才能连接到 GPU。这不仅会占用宝贵的 PCB 面积,增加电路板尺寸和成本,而且长走线会带来显著的信号传输延迟、信号完整性(SI)挑战(如反射和串扰)和更高的驱动功耗。总线宽度受物理可路由通道数的限制(通常最大为 256 位或 384 位)。
HBM 是如何工作的?
预先垂直堆叠的 HBM 模块(包含多个 DRAM 芯片)与 GPU 芯片并排放置在相同的高密度中介层衬底上。
堆叠结构本身大大节省了平面空间(利用 Z 轴)。因此,靠近 GPU(在同一中介层上)导致极短的互连布线长度(毫米级甚至更短)和其他优势,包括:
超高空间利用率
海量存储容量
超宽总线宽度(通过 TSV 和转接板实现)
超低信号延迟
出色的信号完整性
显著降低通信功耗
综上所述,HBM 通过 3D 堆叠 DRAM 封装并与 GPU 在 2.5D 中介层上紧密集成,完美克服了传统 GDDR 的物理限制,从而在带宽和革命性的能效方面实现了数量级的提升。
硅通孔(TSV)技术在高带宽存储器(HBM)中的重要性
在高带宽存储器(HBM)的堆叠结构中,硅通孔(TSV)技术在实现 DRAM 芯片之间的垂直互连方面发挥着至关重要的作用。
TSV 是蚀刻在硅芯片中的微孔(通常直径为 5-50 微米),并填充有铜等导电材料,形成垂直电通道。这些互连具有几个关键优势:
超短互连:TSV 允许信号、电源和接地线直接垂直穿透硅芯片,在相邻 DRAM 层之间提供尽可能短的电气连接路径(约 50-100 微米)。这绕过了传统上使用的较长的引线键合或倒装芯片互连方法,这些方法需要围绕芯片边缘进行布线。
高密度互连:芯片内密集封装了数千到数十万个 TSV,与平面封装方法相比,HBM 实现了更高的互连密度和并行通道数。这支持超宽总线宽度,例如 1024 位或 2048 位,这对于高带宽至关重要。
高速、低功耗运行:较短的垂直连接路径可显著降低信号传输延迟,最大限度地减少信号衰减和失真,并降低驱动互连所需的功率。与具有较长封装引线或 PCB 走线的传统 DRAM 芯片布置相比,基于 TSV 的垂直互连可提供更快、更高效和低功耗的信号传输。
这种先进的垂直互连结构是 HBM 能够同时提供高存储密度、超高带宽和低功耗的基础。
中介层在高带宽存储器(HBM)中的作用
HBM 堆栈和 GPU 芯片不直接焊接到普通 PCB 上。相反,它们被共同集成到称为中介层的精确中间衬底上。中介层本质上是具有超精细布线能力(走线宽度/间距低至 1 微米或更小)的无源硅衬底或高级有机衬底。
中介层在 HBM 系统中起着至关重要的作用:
Bearing Platform: 它为 GPU 芯片和 HBM 堆栈芯片提供了一个物理安装平台。
超高密度互连:其核心价值在于能够在其表面和内部制造大量(数千到数万个)非常窄间距(微米级)的金属迹线(再分布层- RDL)。这些痕迹就像高架公路或密集的高速道路网络。
连接桥:它使用这些超密集走线在非常短的距离(几毫米到几十毫米)内以低损耗精确连接 HBM 堆栈的超宽接口(球栅阵列,通常包含数千个触点)与 GPU 芯片的巨大高速 I/O 端口(微凸块阵列)。
同样,HBM 实现超高带宽的关键不仅仅是提高数据传输的「单通道速度」(时钟频率),而是通过使用 TSV 和中介层共同创建数量惊人的「并行数据通道」(即超宽总线宽度),从而能够一次传输大量数据。
HBM 设计面临的主要挑战是什么?
自第一代 HBM 以来,该技术已经发展了六代,包括 HBM2、HBM2E、HBM3、HBM3E 和计划中中的 HBM4。随着 2025 年 HBM3E 量产竞争的白热化,下一代 HBM4 的竞争已经开始。
在这种持续的技术升级中,封装技术越来越成为竞争的焦点,尤其是在散热瓶颈变得更加明显的情况下。如果堆叠芯片的积热不能得到有效控制,将直接导致性能下降、寿命缩短和功能异常。这使得热管理以及容量和带宽成为高级内存开发的三个核心指标之一。
作为 HBM 高速技术的基石,TSV (Through-Silicon Via)技术通过在 DRAM 芯片上蚀刻数千个微孔来构建垂直电极通道,就像「HBM 摩天大楼」中连接楼层的「高速电梯」一样。
然而,随着 HBM3E 中的堆叠层跃升至 12 层,散热压力和翘曲问题带来了双重挑战。为了保持总厚度,DRAM 芯片需要比 8 层 HBM3 薄 40%,而减薄过程引入了与结构变形相关的新技术障碍。
要突破堆叠超过 12 层的物理限制,混合键合技术可能成为必然选择。虽然该解决方案可以实现微米级 3D 互连,但预计包装成本会增加 30% 以上。
从 HBM4 到 HBM8 的长期路线图
未来 HBM 的 I/O 数量将增加三倍,HBM5、HBM7 和 HBM8 将增加三倍,同时堆栈层、单层容量和引脚速率也将得到改进。此外,键合技术将从目前的微凸块过渡到铜对铜直接键合方法(混合键合)。然而,随着这种代际演变的发生,HBM 堆栈产生的热量将逐渐增加,需要增强的热管理。
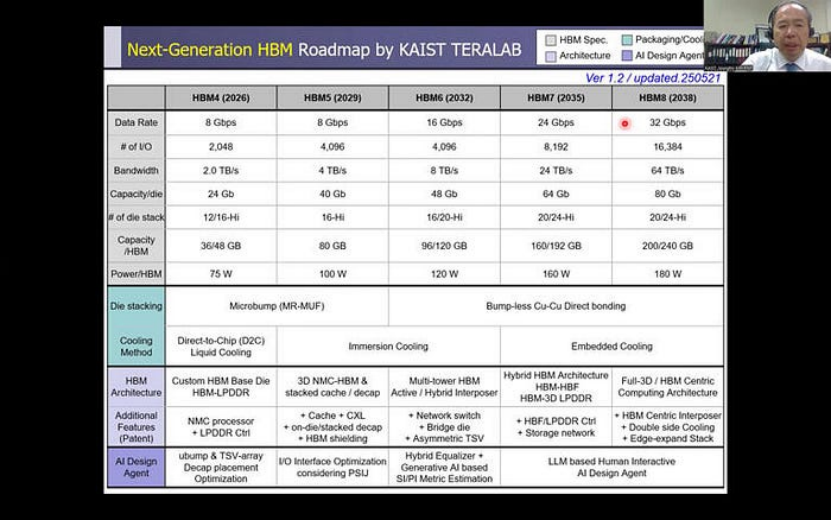
HBM 路线图(来源: KAIST Teralab)
HBM4:集成 LPDDR 控制器
在传统的 HBM 堆栈中,通常具有定制的 DRAM 芯片。
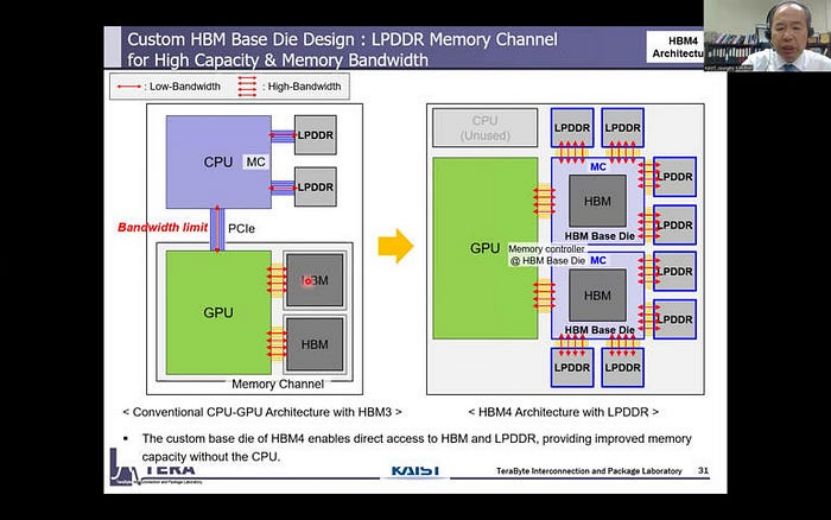 HBM4(来源:KAIST Teralab)
HBM4(来源:KAIST Teralab)
然而,在 HBM4 中,HBM 基础芯片有望集成一个 LPDDR 控制器,为 HBM 存储系统增加一个额外的层,并有效利用传统配置中未使用的容量和带宽资源。
HBM5:面向 AI 工作负载的 NMC 简介
迁移到 HBM5 后,内存堆栈预计将包含 NMC (Near-Memory Computing)模块。这种集成将降低 HBM 和 AI xPU 之间的带宽要求,改善计算定位,并提高整体系统性能和能效。
 HBM5(来源:KAIST Teralab)
HBM5(来源:KAIST Teralab)
HBM6: 双塔结构和 NMC 集成
目前,每个 HBM 堆栈都由一个 Base Die 和一个单塔结构的 DRAM 堆栈组成。
然而,对于 HBM6,预计一个大型 Base Die 将支持两个 DRAM 堆栈,形成双塔物理设计。
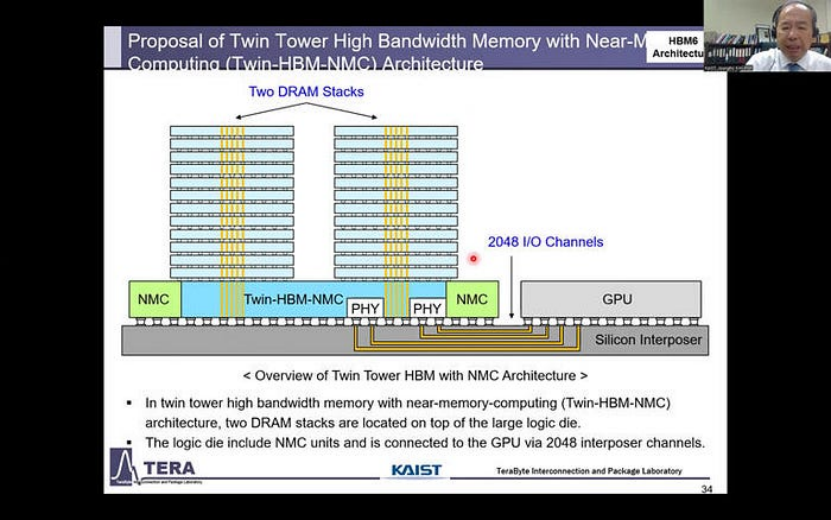 HBM6(来源:KAIST Teralab)
HBM6(来源:KAIST Teralab)
此外,NMC 单元将位于堆栈下方。这一代还将看到从当前的硅中介层/Silicon Bridge 连接过渡到硅玻璃复合中介层,以促进多个 GPU 模块的集成。
HBM7: 多层存储系统和嵌入式冷却
对于 HBM7,预计有两大发展:引入由 HBM 和 HBF(高带宽闪存)组成的多级存储系统,以及在 DRAM 堆栈中集成多功能桥接,以提高信号质量并增加更多功能。
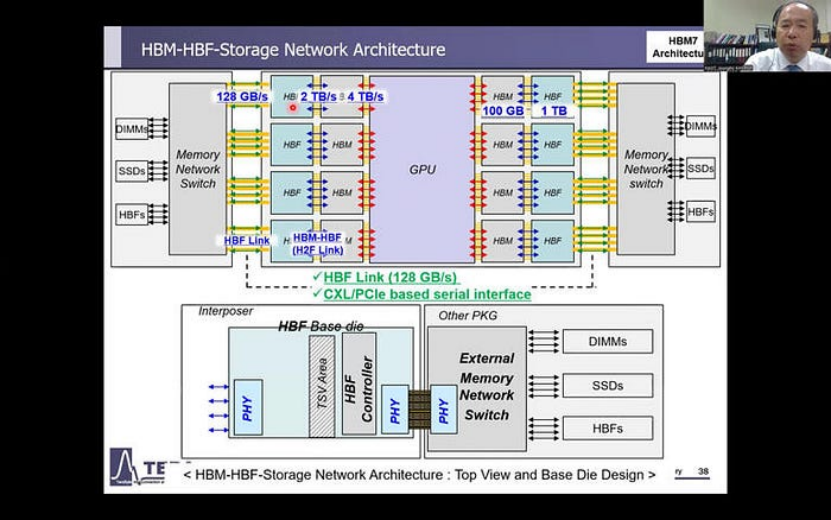 HBM7(来源:KAIST Teralab)
HBM7(来源:KAIST Teralab)
此外,还将引入嵌入式冷却系统,以解决这些系统的高性能功能产生的热量。
HBM8: 增强型芯片复合材料和集成冷却
HBM8 增加了一种复杂的芯片复合材料,它不仅利用了 HBM 内存封装的正面,而且还在背面集成了存储扩展。此外,热管理将紧密集成到结构中,以应对日益增长的热量挑战。
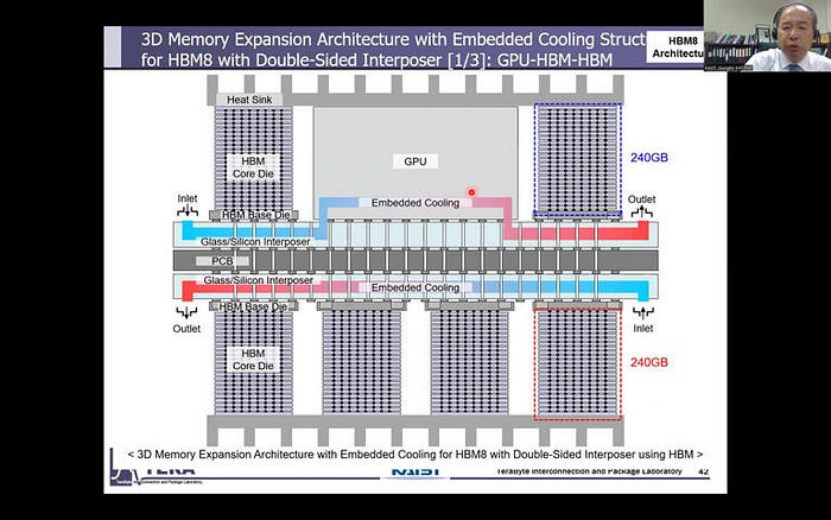 HBM8(来源:KAIST Teralab)展望未来:HBM 在 AI 计算中的未来
HBM8(来源:KAIST Teralab)展望未来:HBM 在 AI 计算中的未来
尽管高带宽内存(HBM)在 AI 计算中发挥着不可替代的作用,但高成本仍然是广泛采用的重大障碍。
为了克服这一挑战,该行业可能会寻求两条可能的途径:
「HBM-Lite」的开发: 此版本旨在通过简化当前的 HBM 架构来优化成本,而不会为要求较低的应用牺牲关键性能。
混合存储架构:一种分层方法,在系统级别将 HBM 与传统内存类型(如 DDR5 和 GDDR7)相结合。在这种设置中,HBM 将管理「热数据」——需要快速处理的高优先级信息——而 DDR5/GDDR7 将处理「冷数据」,即不常访问的信息。这种混合策略可以提供灵活的解决方案,从而有效满足特定需求。对于高端 AI 训练,完整的 HBM 架构将确保所需的吞吐量。对于边缘推理,混合解决方案将优化总拥有成本(TCO),平衡性能与经济性。
KAIST 的长期路线图强调了 HBM 令人兴奋的未来,在内存架构、AI 工作负载和散热解决方案方面不断进步。随着这些创新的展开,HBM 将不断发展以满足高带宽、低延迟应用不断增长的需求,确保其在下一代计算的前沿地位。
关键词: HBM

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码
相关文章
-
-
-
-
-
-
2025-06-17

-
-