全球AI竞赛,美国的优势不止英伟达
人工智能的全球市场竞争中,「主权人工智能」开始成为越来越重要的议题。
关于这个话题的大多数讨论都集中在以下几个核心问题:
世界各国都希望尽快成为万亿美元人工智能市场,并让人工智能成为本国经济增长的关键引擎
各个国家、地区都想要建立反映当地语言、政治和文化的本土人工智能系统
各个国家、地区都认为技术独立是一种应对当前紧张的世界政治格局的正确选择
这种「技术主权」的焦虑,主要来自人们已经深刻认识到技术落要面对的代价。
美国科技的领先带来的福利越来越清晰。20 世纪 80 年代和 90 年代,微软和英特尔等美国科技巨头主宰了 PC 时代,远远超过了亚洲和欧洲的竞争对手。在接下来的几十年里,随着硅谷涌现出一波又一波世界级公司,互联网搜索、社交媒体、电子商务、移动和云计算等领域也出现了同样的循环。
2022 年 11 月 30 日,美国公司 OpenAI 发布了给予大型语言模型(LLM)的 ChatGPT。随后,公众对 AI 技术的关注热情被迅速点燃。彼时,ChatGPT 成为历史上增长最快的消费软件应用程序,也掀起了全球 AI 投资热潮。英国半导体公司 Arm 和 Amadeus Capital Partners 的联合创始人赫尔曼·豪泽 (Hermann Hauser) 表示:「我们非常担心美国会再次遥遥领先」。豪泽曾撰写大量关于欧洲建立技术主权必要性的文章。
如何掌握人工智能的主权?
面对美国再次领先,全世界都在准备 AI 的「粮草」。IDC 数据显示,2022 年全球人工智能 IT 总投资规模为 1,324.9 亿美元,并有望在 2027 年增至 5,124.2 亿美元,年复合增长率为 31.1%。在生成式 AI 市场上,IDC 预测,全球生成式 AI 市场年复合增长率或达 85.7%。2027 年,45% 的企业将掌握并使用生成式 AI 来共同开发数字产品和服务,全球生成式 AI 市场规模将接近 1500 亿美元。
作为 AI 的载体,数据中心的建设如火如荼地进行中。
日本政府投资 725 亿日元,帮助 KDDI、软银和 Sakura 等多家日本公司为 AI 应用建立本地云数据中心。印度政府宣布了一项 12.5 亿美元的计划,名为「IndiaAI Mission」。通过该计划,印度将在全国范围内为创新者、初创企业、学生和教育机构提供便捷的计算能力。
这样的竞赛让英伟达芯片供不应求。当地时间 6 月 18 日,英伟达盘中股价上涨 3.2%,推升该公司市值达到 3.33 万亿美元,市值超越微软。Arm 创始人的担心似乎正在成真。
英伟达产品在 AI 领域的广泛使用成为美国 AI 行业发展的重要优势。即使全球都在进行 AI 投资,美国 AI 投资规模依旧领先于非美国地区的投融资规模。
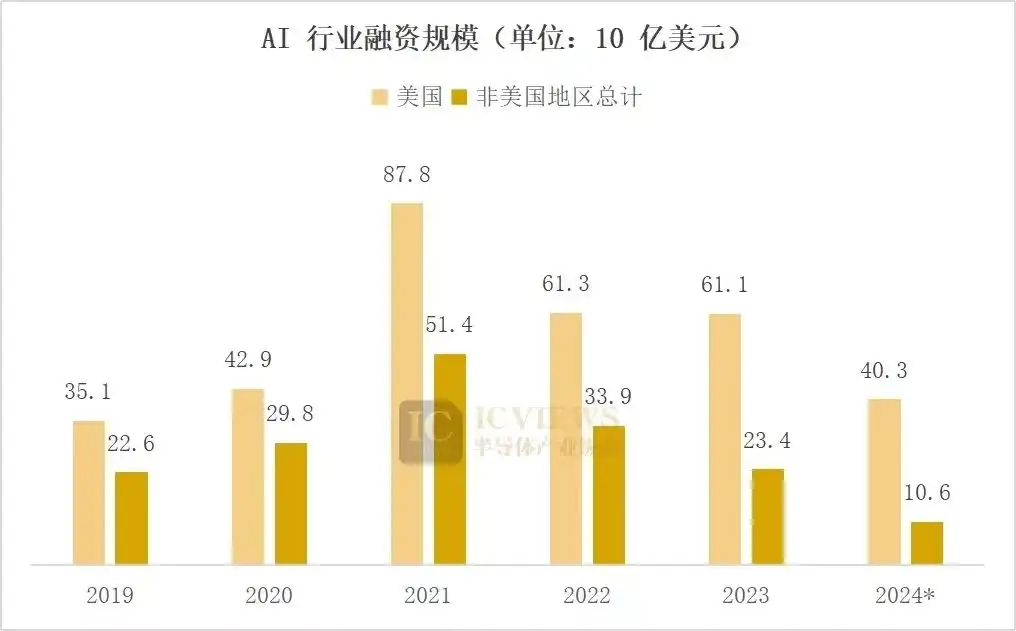
数据来源:PitchBook
当然,英伟达只是美国人工智能,特别是大语言模型产业优势的一部分。基于英语数据库的模型训练,让其他语言的用户在进入 LLM 市场时,面对天然的壁垒。
外国大型语言模型在处理当地语言新词时往往面临理解上的困难。以中文为例,尽管 ChatGPT 等模型能够识别包括中文在内的多种语言,但由于其训练数据主要基于英文文本,因此在处理非英语语言时,可能会遭遇语言结构、语法等方面的挑战,从而影响其输出效果。近日,一篇论文指出,相较于直接使用非英文语言作为提示词,将非英文语言先翻译成英文再进行处理的输出效果更佳。
此外,值得注意的是,中文与英文在训练与推理方面存在显著的「不公平性」。由于中文语言的复杂性,AI 模型在运用中文数据进行准确训练和推理时可能会遭遇挑战,并且增加了中文模型应用和维护的难度。同时,对于开发大模型的公司来说,构建中文大模型由于需要额外的资源,或许就得承担更大的成本。
具体而言,中文的 token 数通常比英文多出两倍以上,这主要源于中文词汇的丰富含义和灵活的语言组成。中文词汇常常具有深厚的文化内涵和丰富的语境意义,这极大地增加了语言的歧义性和处理难度。相比之下,英语的语法结构相对简单,这在一定程度上使得英语在某些自然语言处理任务中相较于中文更易于被理解和处理。而 token 数量就是成本,毕竟使用 OpenAI 的 GPT-4 模型 API,每输入 1 千 token 至少要花费 0.03 美元。
针对上述观点,有工程师指出,中文与英文在模型训练的基本原理上并无本质区别。两者均是将语句拆解为独立的单词,随后将这些单词纳入向量数据库,并通过神经网络进行深度学习。实际上,OpenAI 在初创时期亦曾面临效果不佳的困境,最终之所以能够取得显著成效,主要得益于数据量的不断积累与扩充。
因此,无论是哪种语言的大模型,其训练的核心原理均保持一致,并不会因语言差异而导致训练难度的显著变化。美国在大语言模型领域并未展现出特别的优势,其之所以表现更为出色,主要得益于庞大的数据量。相比之下,中国在语料丰富性方面具备一定优势。然而,由于中文处理过程中涉及的 token 数量相对较多,这也导致了模型在运行过程中所需的内存和计算资源相应增加,进而使得成本有所上升。目前,国内通义千问在相关领域表现优异,这同样得益于其拥有大量的数据支持。
尽管数据量是最重要的因素,全球各地也都在围绕本国语言去发展大语言模型。
非英语大模型的进击
HyperClova X 背后的另一个重要动机是追求更低的计算成本。使用 LLM 的费用通常取决于它们被要求处理的数据量,它们将这些数据分解成为标记的单词或字符块。标记越多,成本就越高。
韩国互联网巨头 Naver 正积极研发其自有的大型语言模型——HyperClova X,并计划将其广泛应用于旗下各类服务中。此模型的引入,预计将深刻影响这个高度数字化的国家内,Naver 众多应用程序的运行与体验。Naver 的业务范畴广泛,涵盖了电子商务、搜索引擎、出行服务等多个领域。
为确保 HyperClova X 的输出内容能够充分契合韩国国内受众的文化背景,Naver 特别组建了一支专业的安全专家团队。Naver 研究主管 Kang Min Yoo 指出,韩国社会拥有丰富的新词文化,这些新词往往令外国大型语言模型难以捉摸。同时,韩国民众在对待政府调控房价等社会问题上的态度,相较于美国民众,显得更为支持。因此,HyperClova X 在回应相关问题时,能够比非韩国模型更准确地反映这些社会价值观。
Kang Min Yoo 表示,大型语言模型在处理问题时,往往会根据上下文和地理位置的不同,得出不同的答案。这也是 HyperClova X 在研发过程中需要重点考虑的因素之一。
当然,追求更低的计算成本也是推动 HyperClova X 研发的重要动力之一。在使用大型语言模型时,费用通常与所需处理的数据量成正比。而数据量的多少,又直接决定了模型需要处理的标记数量。因此,减少标记数量,降低计算成本,成为 HyperClova X 研发过程中的一项重要任务。
Naver 宣称,其模型相较于 OpenAI 的 GPT-3 含有 6,500 倍之多的韩语数据,从而能够将韩语查询分解为更少的标记,进而实现成本的有效降低。据对西方大型语言模型 LLM 的独立分析显示,处理非英语语言的查询通常需要比英语更多的标记。
在印度,有着类似的故事上演。人工智能初创公司 Sarvam AI 的创始人维韦克·拉加万(Vivek Raghavan)正在致力于构建印地语专用的模型 OpenHathi,以提升其在印地语环境中的运行效率。尽管印地语是全球使用最为广泛的语言之一,但拉加万指出,印地语在 Common Crawl 这一网络数据存储库中所占的数据比例仅为约 0.17%。而 Common Crawl 正是许多全球最大型的人工智能公司用于训练其模型的重要资源。
本地 AI 模型降低成本的有效性已引起了知名投资者的广泛关注。硅谷著名风险投资家 Vinod Khosla 透露,他通常不会投资于与 OpenAI 及其他行业领先者直接竞争的公司,因为他认为新创公司难以在竞争中占得先机。然而,他却为 Sarvam AI 和日本初创公司 Sakana AI 破例,对这两家公司进行了投资。谈及印度语言,Khosla 表示,基于英语的人工智能系统在处理印度语言时的效率往往比专门针对这些语言构建的模型低三到五倍。他强调在印度,降低成本至关重要,使用模型的每分钟成本必须达到最低。
欧洲的 AI 布局
在激烈的竞争中,欧洲企业值得注意。要知道,如果溯源到人工智能的历史,欧洲才是这一技术的发源地。英裔加拿大人 Geoffrey Hinton 和法国出生的 Yann LeCun,两人被称为「人工智能教父」。
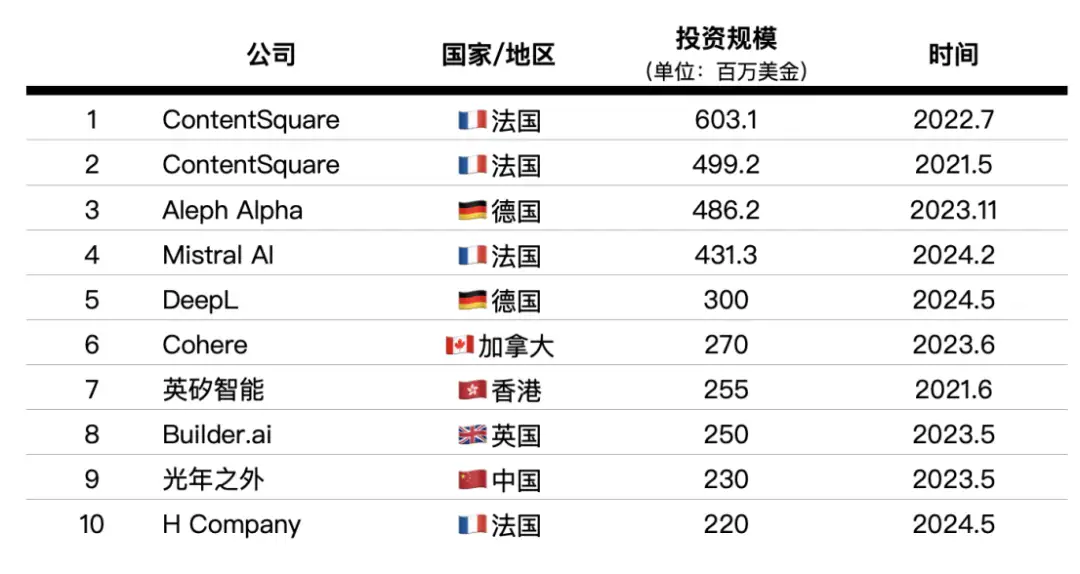
非美国地区 AI 投资规模前十案例
根据上表所呈现的数据,欧洲在人工智能领域的投资规模明显领先于其他地区。此外,在过去的十年中,欧洲的监管机构着手制定更为严谨且严格的基础规则,旨在让科技巨头公司遵从其指导原则。欧盟及其成员国,包括德国和英国在内,已经通过了多项隐私法规,比如 2016 年实施的《通用数据保护条例》,旨在严惩滥用消费者个人数据的互联网公司。
最近,欧盟更是颁布了《数字市场法案》,以遏制科技领域的「守门人」通过不正当手段打压规模较小的竞争对手。
欧洲人工智能的初创企业日益增多,并逐渐吸引了硅谷投资者的关注。法国版的 OpenAI——Mistral,迄今为止已筹集了超过 10 亿美元的资金,其中包括本周早些时候宣布的一轮融资,其估值据报道已达到 62 亿美元。此外,法国人工智能公司 H(原名 Holistic)也从前谷歌首席执行官埃里克·施密特以及 LVMH 首席执行官伯纳德·阿诺等业界知名人士处筹集了 2.2 亿美元的资金。
但又如近现代西方政治、经济的变化一样,美国却再次「反超」了欧洲。这或许与欧洲文化有关。欧洲的商业文化更加侧重于谨慎而非单纯的增长,这种倾向可能在一定程度上导致欧洲在突破性技术领域的成功案例相较于美国有所减少。欧洲历来不乏杰出的大学与卓越的人才,然而,这些优秀的人才和学术资源在商业化方面并未得到充分有效地利用。
国内方面,不久前商汤科技发布了首个粤语大模型 Sensechat。可以发现 LLM 的竞争已经从硬件到软件全面铺开。在这场 AI 主权的竞争中,美国正在承受来自全世界的追赶。
关键词: AI

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码
相关文章
-
-
-
-
-
-
-
2024-07-03
-