ARM存储器之:高速缓冲存储器Cache
15.3.3Cache工作原理
Cache的基本存储单元为Cache行(Cacheline)。存储系统把Cache和主存储器都划分为相同大小的行。Cache与主存储器交换数据是以行为基本单位进行的。每一个Cache行都对应于主存中的一个存储块(memoryblock)。
Cache行的大小通常是2L字节。通常情况下是16字节(4个字)和32字节(8个字)。如果Cache行的大小为2L字节,那么对主存的访问通常是2L字节对齐的。所以对于一个虚拟地址来说,它的bit[31∶L]位,是Cache行的一个标识。当CPU发出的虚拟地址的bit[31∶L]和Cache中的某行bit[31∶L]相同,那么Cache中包含CPU要访问的数据,即成为一次Cache命中。
为了加快Cache访问的速度,又将多个Cache行划分成一个Cache组(CacheSet)。Cache组中包含的Cache行的个数通常也为2的N次方的倍数。为了方便起见,取N=S。这样,一个Cache组中就包含2S个Cache行。这时,虚拟地址中的bit[L+S-1∶L]为Cache组的标识。虚拟地址中余下的位bit[31∶L+S]成为一个Cache标(Cache-tag)。它标识了Cache行中的内容和主存间的对应关系。
图15.10显示了Cache的访问过程。
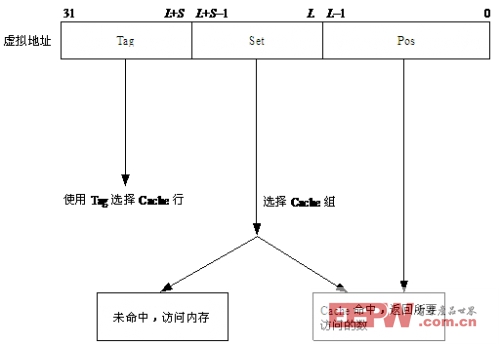
图15.10Cache访问过程
15.3.4Cache与主存的关系
在Cache中采用地址映射将主存中的内容映射到Cache地址空间。具体的说,就是把存放在主存中的程序按照某种规则装入到Cache中,并建立主存地址到Cache地址之间的对应关系。而地址变换是指当程序已经装入到Cache后,在实际运行过程中,把主存地址变换成Cache地址。
地址的映射和变换是密切相关的。采用什么样的地址映射方法,就必然有与之对应的地址变换。
常用的地址映射和变换方式包括直接映射和变换方式、组相联映射和变换方式以及全相联和变换方式。
(1)直接(direct-mapped)映射方式
直接映射是一种最简单,也是最直接的映射方式。主存中的每个地址都对应Cache存储器中惟一的一行。由于主存的容量远远大于Cache存储器,所以在主存中很多地址被映射到同一个Cache行。
图15.11显示了主存与Cache的直接映射关系。
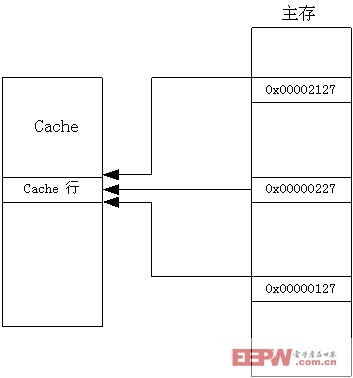
图15.11主存和Cache的直接映射
直接映射Cache是一种简单的解决方法,但这种设计使得每个主存块在Cache中只有一个特定的行可以存放。如果程序同时用到对应于Cache同一行的两个主存块,那么就会发生冲突,冲突的结果是导致Cache行的频繁变换。这种由直接映射导致的Cache存储器中的软件冲突称为颠簸(thrashing)问题。
(2)组相联映射方式
为了减少颠簸问题,有些Cache使用了组相联的映射策略。在组相联的地址映射和变换中,把主存和Cache按同样大小划分成组(set),每个组都由相同的行数组成。
由于主存的容量比Cache容量大得多,因此,主存的组数要比Cache的组数多。从主存的组到Cache的组之间采用直接映射方式。主存中的一组与Cache中的一组之间建立了之间映射方式后,在两个对应的组内部采用全相联映射方式。
在ARM中采用的是组相联的地址映射和变换方式。如果Cache的行大小为2L,则同一行中各地址的bit[31∶L]是相同的。如果Cache中组的大小(每组中包含的行数)为2S,则虚地址位bit[L+S∶L]用于选择Cache中的某个组。
图15.12显示了一个Cache与主存储器的组相联映射
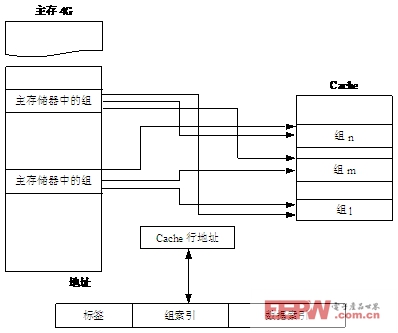
图15.12Cache与主存储器组相联映射
拥有相同组索引的Cache行称为组相联的(setassociative)。主存中的程序或代码段可以在不影响程序执行的情况下被分配到Cache中的某一组中。也就是说,将数据或代码存入Cache行中的操作不会影响程序的执行。
(3)全相联映射方式
随着Cache控制器的相联度的提高,冲突的可能性减少了。理想的目标是,尽量提高组相联程度,使主存地址能够映射到任意Cache行。这样的Cache被称为全相联Cache。然而,随着相联度的提高,与之相匹配的硬件的复杂度也在提高。硬件设计者提高Cache相联度的一种方法就是使用内容寻址寄存器CAM(ContentAddressableMemory)。
CAM使用一组比较器,以比较输入的标签地址和存储在每一个有效Cache行中的标签位。CAM采取了与RAM相反的工作方式;RAM在得到一个地址后再给出数据;而CAM则是在检测到给定的数据值在存储器中后,再给出该数据的地址。使用CAM允许同时比较更多的地址中的标签位,从而增加了可以包含在一个组中的Cache行数。
在ARM920T和ARM940T存储器核中,ARM使用了CAM来定位地址中的标签域。ARM920T和ARM940T中的Cache是64组组相联的。图15.13所示为ARM940T的Cache结构图。Cache控制器把地址标签域作为CAM的输入,它的输出选择了包含有效Cache行的组。
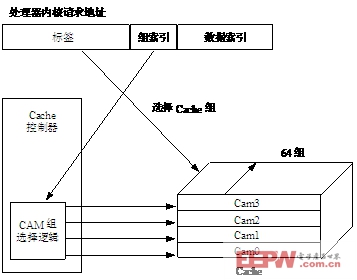
图15.13ARM940T64路组相联Cache
访问地址的标签部分被作为4个CAM的输入,输入标签的同时与存储在64组中的所有Cache标签比较。如果有一个匹配,那么数据就由Cache寄存器提供;如果没有匹配,存储器就会产生一个失效(misss)信号。
控制器使用组索引位(setindex)在4个CAM中选择一个。被选中的CAM会在Cache存储器中选择一个Cache行,该地址的数据索引部分(dataindex)在该Cache行中选择出所需的字、半字或者字节。
15.3.5Cache的写策略
当CPU更新了Cache内容时,要将结果写回到主存中,通常有两种方法:
·直写法(write-through);
·回写法(write-back)。
直写法是指,当CPU在执行写操作时,必须把数据同时写入Cache和主存,以确保Cache和主存数据一致。在这种写策略下,处理器在每次写Cache时也要写相应的主存单元。由于要访问主存,直写法的速度比回写法要慢一些。
回写法是指,当处理器和写Cache命中时,只向Cache存储器写数据,而不立即写入主存。这样,主存储器与相应的Cache行数据有可能不一致。Cache中的数据是新的,而主存中的数据可能是较早的、没有被更新过的。
配置成回写法的Cache要使用Cache行的状态信息块中的一个或多个脏位(dirtybit)。当回写Cache控制器向Cache存储器中的某一行写入数据时,它会将脏位设置为1。如果控制器内核此后访问该Cache行,那么通过脏位的状态就可以知道该Cache行中含有主存储器中没有的数据。如果Cache控制器要将一个脏位被设置的Cache行替换出Cache存储器,那么该Cache行数据会自动被写入主存单元中。控制器通过这种方法来防止只存在于Cache中而主存中没有的重要信息的丢失。
表15.12比较了直写法和回写法的优缺点。
表15.12 直写法与回写法
写策略 | 直写法 | 回写法 |
可靠性 | 高 | 低 |
与主存的通信量 | 多 | 少 |
控制的复杂性 | 简单 | 复杂 |
硬件实现代价 | 大 | 小 |
下面分析产生这些性能差异的原因。
·可靠性。直写法要优于回写法。这是因为直写法始终保证Cache是主存的正确副本。当Cache发生错误时,可以从主存中纠正。
·与主存的通信量。一般情况下,回写法少于直写法。这是因为,一方面,Cache的命中率很高,对于回写法来说,CPU绝大多数操作只需要写Cache,不必写主存。另一方面,当Cache失效时,要将Cache中的行替换到主存,而直写法每次只写一个字到主存。总的来说,由于直写法在每次写Cache时,同时写主存,从而增加了写操作的开销。而回写法是把与主存的数据交换集中到一次主存操作,可能要一次性的进行多个字的操作。
·控制的复杂性。直写法必回写法简单。直写法在Cache的行状态表中不需要修改位。同时,直写法的纠错技术相对简单。
·硬件代价。回写法比直写法好。因为直写法中,每次写操作都要写主存,因此为了节省写主存所花费的时间,通常要采用一个高速小容量的缓存存储器,把要写的数据和地址写到这个缓存中。在每次读主存时,也要首先判断所读的数据是否在这个缓存中。而回写法不需要上述操作,相对硬件代价要小。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码