基于FPGA 的多时钟片上网络设计
3 性能分析
利用Virtex-4 系列中XC4VLX100-11[4]设备进行设计, 利用Xilinx ISE 8.2i 进行综合布局布线。使用ModelSim 6.1c[5]验证所设计的功能。设置了单一时钟和多时钟进行了模拟,分析多时钟片上网络的性能。由于路由器是直接连接到内核, 所以没必要考虑片与片之间的延时而去估计最高的频率。所设计是由一个路由功能模块(RFM)执行[6],用以准确地估计工作频率,基本路由器的单机版工作频率可到达357MHz。因此8bits 通道的路由器的吞吐量最高可达2.85Gbits/s。在所设计的路由器中, 头数据片前进到下一个节点,而剩下的数据片以流水线方式流通。在计划中,网络延时仅仅与路径长度H(跳跃点数量)有关。在信道争用的情况下,网络延时L 可以用以下方式计算:
L = 7×H + B/w (1)
公式(1)中,B 是数据包的字节数,w 是每个时钟周期转换的字节数。参数7 是在多时钟片上网络路由器中安装在每个路由器跳延迟支付。这个延时是因为基于数据包中的头数据片的解码和仲裁执行所导致的。
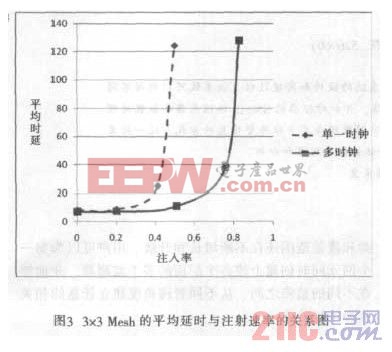
为了*估所设计的多时钟架构的性能, 将利用所设计的路由器的VHDL 模型,模拟一个3×3Mesh 结构,在本身频率下执行包装产生的数据包。路由器的频率值会在拓扑结构合成,布局和布线阶段完成之后得出。对于不同的配置(资源的可用性、跨路由器的距离、bRAM/dRAM FIFO 的版本),路由器的频率可以降低高达18%[6]。图3 显示了单一时钟与多时钟,在延时与注射速率关系中的曲线图。在单一时钟时,网络的频率为286MHz。而在多时钟时, 频率的范围是从286MHz~357MHz。图3 中,X 轴表示的注射率是在一个周期内每个节点注入flit 的数量。Y 轴曲线测量的是每个实例中数据包的平均延时。可以看出,所提出的多时钟片上网络相比单一时钟片上网络的性能显着增加。
4 结语
本文介绍了一个基于FPGA 的高效率多时钟的虚拟直通路由器,通过优化中央仲裁器和交叉点矩阵,以争取较小面积和更高的性能。同时,扩展路由器运作在独立频率的多时钟NoC 架构中,并在一个3×3Mesh 的架构下实验,分析其性能特点,比较得出多时钟片上网络具有更高的性能。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码