Helium 技术讲堂 | 为何不直接采用 Neon?
Arm Helium 技术诞生的由来
为何不直接采用 Neon?
作者:Arm 架构与技术部 M 系列首席架构师兼研究员 Thomas Grocutt
经过 Arm 研究团队多年的不懈努力, Arm 于 2019 年推出了适用于 Armv8‑M 架构的 Arm Cortex-M 矢量扩展技术 (MVE)——Arm Helium 技术。 起初,当我们面临 Cortex‑M 处理器的数字信号处理 (DSP) 性能亟待提升的需求时,我们首先想到的是采用现有的 Neon™ 技术。然而,面对典型的 Cortex‑M 应用的面积限制条件下又需要支持多个性能的需求,意味着我们仍需从头开始。作为一种较轻的惰性气体,以氦气 (Helium) 作为研究项目的名称似乎再合适不过了。该研究项目主要针对中端处理器,旨在实现数据路径宽度增加两倍的情况下将性能提高四倍,而这正与氦气的原子量 (4) 和原子序数 (2) 不谋而合。最终,在许多数字信号处理 (DSP) 和机器学习 (ML) 内核上,我们成功地实现了提升四倍的目标。毋庸置疑, “Helium” 已经深入人心,成为 Cortex-M 处理器系列 MVE 的品牌名。
要想打造具备良好 DSP 性能的处理器,主要关键在于可为其提供足够的数据处理带宽。 在 Cortex‑A 处理器上,128 位 Neon 负载可以轻松地从数据缓存中直接提取。但是,Cortex‑M 处理器通常没有缓存,而是使用低延迟静态随机存取存储器 (SRAM) 作为主内存。对于许多系统来说,无法将 SRAM 路径(通常只有 32 位)拓宽到 128 位,因此导致面临内存操作停滞长达四个周期的可能性。同样,乘加 (MAC) 指令中使用的乘法器需要很大的面积,在小型 Cortex‑M 处理器上使用四个 32 位乘法器是不切实际的。就面积限制层面而言,最小的 Cortex-M 处理器与能够乱序执行指令且功能强大的 Cortex‑A 处理器的大小可能相差几个数量级。 因此,在创建 M 系列架构时,我们必须认真考虑充分利用每一个 gate。 为了充分利用现有硬件,我们需要确保高成本资源(如通往内存的连接和乘法器)在每个周期都保持同时繁忙的状态。在高性能处理器(如 Cortex‑M7)上,可以通过矢量 MAC 双发射来达成这一目标。此外,还有一个重要的目标,即在一系列不同的产品上提高 DSP 性能,而不仅局限于高端产品上。想要解决以上这些问题,需要借鉴参考几十年前的矢量链理念中的一些技术。
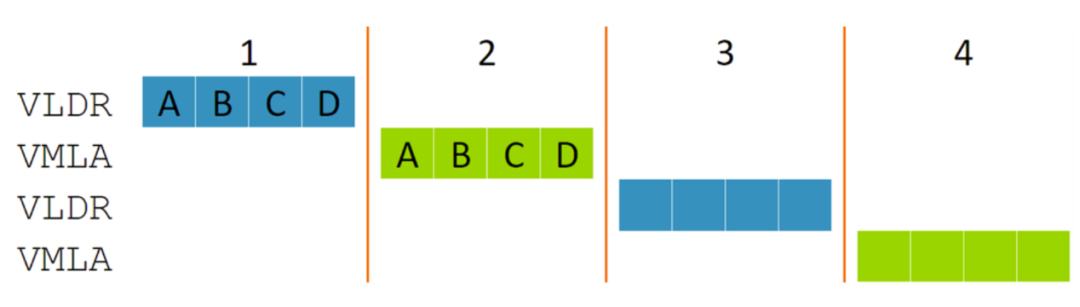
上图显示了在四个时钟周期内交替执行的矢量负载 (VLDR) 和矢量 MAC (VMLA) 指令序列。这需要 128 位宽的内存带宽和四个 MAC 块,并且它们有一半时间处于空闲状态。可以看到,每条 128 位宽的指令被分成大小相等的四个片段,MVE 架构称之为“节拍”(标为 A 至 D)。无论元素大小如何,这些节拍始终是 32 位计算值,因此一个节拍可以包含一个 32 位 MAC,或四个 8 位 MAC。由于负载和 MAC 硬件是分开的,这些节拍的执行可以重叠,如下图所示。
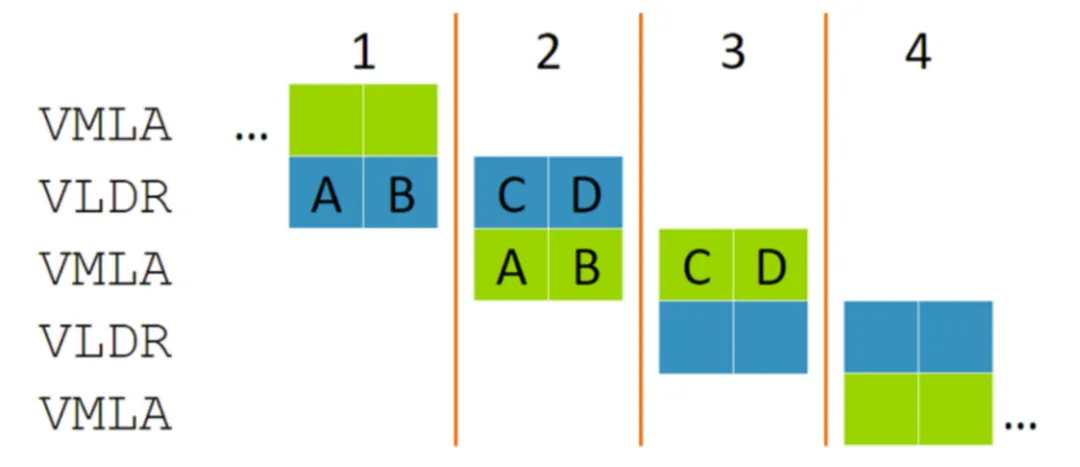
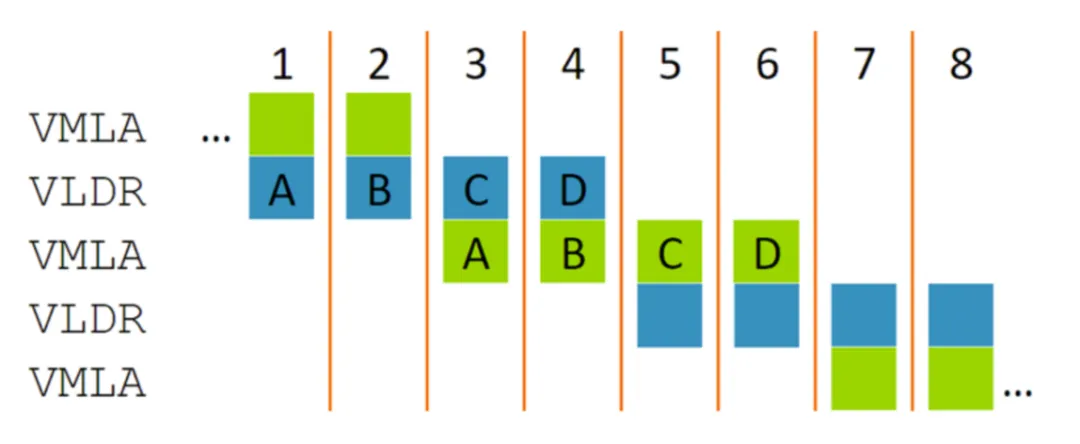
即使 VLDR 加载的值被随后的 VMLA 使用,指令仍可以重叠。这是因为 VMLA 的节拍 A 只依赖于上一个周期发生的 VLDR 的节拍 A,因此节拍 A 和 B 与节拍 C 和 D 便会自然重叠。在这个例子中,我们可以获得与 128 位数据带宽处理器相同的性能,但硬件数量只有后者的一半。 “节拍式”执行的概念可以高效地实施多个性能点。 例如,下图显示了只有 32 位数据带宽的处理器如何处理相同的指令。这一点充满吸引力, 因为它能使单发射标量处理器的性能翻倍(在八个周期内对八个 32 位值加载和执行 MAC),但却没有双发射标量指令那样的面积和功耗需求。
MVE 支持扩展到每周期四拍的实现方式,此时节拍式执行将简化为更传统的 SIMD 方法。这有助于在高性能处理器上保持可控的实现复杂度。
节拍式执行听起来很不错,但也会给架构的其他部分带来一些值得关注的挑战。
由于多条部分执行的指令可以同时运行,因此中断和故障处理可能会变得相当复杂。 例如,如果上图中 VLDR 的节拍 D 出现故障,通常情况下,实施必须回滚 VMLA 的节拍 A 在上一周期对寄存器文件的写入。我们的理念是让每个 gate 都物尽其用,而在回滚的情况下缓冲旧数据值与这一理念相悖。为了避免这种情况,处理器会针对异常情况存储一个特殊的 ECI 值,用于指示已经执行了后续指令的哪些节拍。在异常返回时,处理器便以此来确定要跳过哪些节拍。能够快速跳出指令而无需回滚或等待指令完成,基于此保持 Cortex-M 具备的快速和确定性中断处理能力。
如果指令会跨越节拍边界,我们又会遇到时间跨越问题。 这种交叉行为通常出现在拓宽/缩窄运算中。Neon 架构中的 VMLAL 指令就是一个典型的例子,它可以将 32 位值矢量乘加到 64 位累加器中。遗憾的是,为了保持乘法器输出的完整范围,通常需要进行这类拓宽运算。MVE 使用通用的 “R” 寄存器文件来处理累加器,从而解决了这一问题。此外,这样还减少了对矢量寄存器的寄存压力,使 MVE 只需使用 Neon 架构中一半的矢量寄存器就能获得良好的性能。在矢量架构中,通常不会像 MVE 一样广泛使用通用的寄存器文件,因为寄存器文件往往与矢量单元相距甚远。在乱序执行指令的高性能处理器上尤为如此,因为物理距离过大会限制性能。不过,正因如此,我们恰恰能够将典型 Cortex‑M 处理器的较小规模特性转化为我们的优势。
为确保重叠执行达到良好的平衡且无停滞,每条指令都应严格描述 128 位的工作,不能多也不能少。 由此也会带来一些挑战。
凭借研究员们辛勤不懈的努力,以及充分参考架构书籍中所涉的所有内容,MVE 成功地将一些非常苛刻的功耗、面积和中断延迟限制转化为优势。
我们将在下一篇 Helium 技术文章中深入探讨一些复杂而又有趣的交错加载/存储指令。持续关注 Helium 技术讲堂,我们下期再见!

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码