使用QDR-IV设计高性能网络系统——第一部分
流媒体视频、云服务和移动数据推动了全球网络流量的持续增长。为了支持这种增长,网络系统必须提供更快的线路速率和每秒处理数百万个数据包的性能。在网络系统中,数据包的到达顺序是随机的,且每个数据包的处理需要好几个存储动作。数据包流量需要每秒钟访问数亿万次存储器,才能在转发表中找到路径或完成数据统计。
数据包速率与随机存储器访问速率成正比。如今的网络设备需要具有很高的随机访问速率(RTR)性能和高带宽才能跟上如今高速增长的网络流量。其中,RTR是衡量存储器可以执行的完全随机存储(读或写)的次数,即随机存储速率。该度量值与存取处理过程的处理位数无关。RTR是以百万次/每秒(MT/s)为单位计量的。
相比于高性能网络系统需要处理的随机流量的速率,当今高性能DRAM能够处理的要少一些。QDR-IV SRAM旨在提供同类最佳的RTR性能,以满足苛刻的网络功能要求。图1量化了QDR-IV相比于其它类型的存储器在RTR性能方面的优势。即使与最高性能的存储器相比,QDR-IV仍能提供两倍于后者的RTR性能,因此,它是那些需要执行要求苛刻的操作-如更新统计数据、跟踪数据流状态、调度数据包、进行表查询-的高性能网络系统的理想选择。
在本系列的第一部分中,我们将探讨两种类型的QDR-IV存储器、时钟、读/写操作和分组操作。

不同类型的QDR-IV:XP和HP
QDR-IV 有两种类型。HP在较低频率下工作,而且不使用分组操作。 XP面向最高性能的应用,可以使用分组操作方案,并在较高频率下工作。
QDR-IV的读写时延由运行速度决定。表1 定义了工作模式和每个模式所支持的频率。

QDR-IV SRAM具有两个端口,即端口A和端口B。由于可以独立访问这两个端口,所以对存储器阵列进行的任何读/写访问组合均可得到最大的随机数据传输速率。在QDR-IV中,对每个端口进行访问时需要使用双倍数据速率的通用地址总线(A)。端口A的地址在输入时钟(CK)的上升沿上被锁存,而端口B的地址在输入时钟(CK)的下降沿上或在CK#的上升沿上被锁存。控制信号(LDA#、LDB#、RWA#和RWB#)以单倍数据速率(SDR)工作,并用于确定执行读操作还是写操作。两个数据端口(DQA和DQB)均配备了双倍数据速率(DDR)接口。该器件具有2字突发的架构。器件的数据总线带宽为 × 18或 × 36。
QDR-IV SRAM包括指定为端口A和端口B的两个端口。因为对两个端口的访问是独立的,所以对于对存储器阵列的读/写访问的任何组合,随机事务速率被最大化。 对每个端口的访问是通过以双倍数据速率(即时钟的两个边沿)运行的公共地址总线(A)。 端口A的地址在输入时钟(CK)的上升沿锁存,端口B的地址在CK的下降沿或CK#的上升沿锁存。 控制信号(LDA#,LDB#,RWA#和RWB#)以单数据速率(SDR)运行,它们决定是执行读操作还是写操作。 两个数据端口(DQA和DQB)都配有双倍数据速率(DDR)接口。 该器件采用2字突发架构。 它提供×18和×36数据总线宽度。
QDR-IV XP SRAM器件具有一个组切换选项。分组操作一节描述了如何使用组切换,让器件能够以更高的频率和RTR工作。
时钟信号说明
CK/CK#时钟与以下地址和控制引脚相关联:An-A0、AINV、LDA#、LDB#、RWA#以及RWB#。CK/CK#时钟与地址和控制信号中心对齐。
DKA/DKA#和DKB/DKB#是与输入写数据相关联的输入时钟。这些时钟与输入写数据中心对齐。
根据QDR-IV SRAM器件的数据总线宽度配置,表2显示了输入时钟与输入写数据之间的关系。为了确保指令和数据周期的正确时序,并确保正确的数据总线返回时间,DKA/DKA#和DKB/DKB#时钟必须符合各自数据表中给出的CK‑to‑DKx斜率 (tCKDK)。

QKA/QKA#和QKB/QKB#是与读取数据相关联的输出时钟。这些时钟与输出读取数据边沿对齐。
QK/QK#是数据输出时钟,由内部锁相环(PLL)生成。它与CK/CK#时钟同步,并符合各自数据表中给出的CK‑to‑QKx斜率 (tCKQK)。
根据QDR-IV SRAM器件的数据总线带宽的配置情况,表3显示了输出时钟与读取数据之间的关系。

读/写操作
读和写指令由控制输入(LDA#、RWA#、LDB#和RWB#)和地址输入驱动。在输入时钟(CK)的上升沿上对端口A控制输入进行采样。在输入时钟的下降沿上对端口B控制输入进行采样。
表4显示的是端口A和端口B的读/写操作条件。

如图2 和图3 所示,对于QDR-IV HP SRAM,端口A的读取数据在CK的上升沿后整五个读取延迟(RL)时钟周期后才从DQA 引脚上输出;对于QDR-IVXP SRAM,则需要八个读延迟(RL)时钟周期。CK信号的上升沿发生,同时读取指令发出,经过指定的RL时钟周期后才可获取数据。
对于QDR-IV HP SRAM,端口A的写入数据在CK的上升沿后整三个写入延迟(WL)时钟周期才传输至DQA 引脚;对于QDR-IV XP SRAM,则需要五个写延迟(WL) 时钟周期。CK信号的上升沿发生,同时写入指令发出,经过指定的RL时钟周期后才可获取数据。
对于QDR-IV HP SRAM,端口B的读取数据在CK的上升沿后整五个RL 时钟周期才从DQB引脚上输出;对于QDR-IV XP SRAM,则需要八个RL 时钟周期。CK信号的上升沿发生,同时读取指令发出,经过指定的RL时钟周期后才可获取数据。
对于QDR-IV HP SRAM,端口B的写入数据在CK的上升沿后整三个WL 时钟周期才传输至DQB引脚;对于QDR-IV XP SRAM,则需要五个WL 时钟周期。CK信号的上升沿发生,同时写入指令发出,经过指定的RL时钟周期后才可获取数据。
QVLDA/QVLDB 信号表示相应端口上的有效输出数据。在总线上驱动第一个数据字的半周期前置位QVLDA 和QVLDB信号,并在总线上驱动最后一个数据字的半周期前取消置位它们。最后数据字后的数据输出是三态的。

旨在实现高速运行的分组操作
QDR-IV XP SRAM 的设计是为了支持频率更高的八组模式(最大工作频率 = 1066 MHz),而QDR-IV HP SRAM 则支持频率较低的无分组模式(最大工作频率 = 667 MHz)。
QDR-IV XP 中较低的三个地址引脚(A2、A1 和A0)选择了在读或写期间将要访问的组。唯一的分组限制是在每个时钟周期内该组仅能被访问一次。QDR-IV XP SRAM 的组访问规则要求在端口B 上访问的组地址与在端口A 上访问的组地址不相同。
如果不符合分组限制,那么由于在时钟的上升沿时已经对读/写操作进行采样,在端口A 上则不会限制读/写操作,但会禁止端口B 上的读/写操作。QDR-IV HP SRAM 并没有任何分组限制。

QDR-IV XP SRAM 上的分组限制可作为某些应用的一个优点,在这些应用中,存储器中的每一组都有不同的用途,并且都不能在同一个时钟周期中被访问两次。一个网络路由器能够在QDR-IV XP SRAM 的每一组内储存不同的路由表便是一个实例。如果在同一个时钟周期内特定的路由表仅能被访问一次,则有可能实现高TRT (随机数据传输速率)。在该情况下,工作频率为1066 MHz 时,可获得的最高随机数据传输速率为2132 MT/s。
分组限制不会影响到数据传输速率的另一种情况是使用物理层上的多个端口进行设计,通过每一个端口可以直接访问存储器中一组。这些端口将被复用到QDR-IV XP SRAM 的端口A 和端口B。在该设计中,因为每一个组都连接了物理层上不同的端口,因此任何一个组都不能在同一个时钟周期内被访问两次。
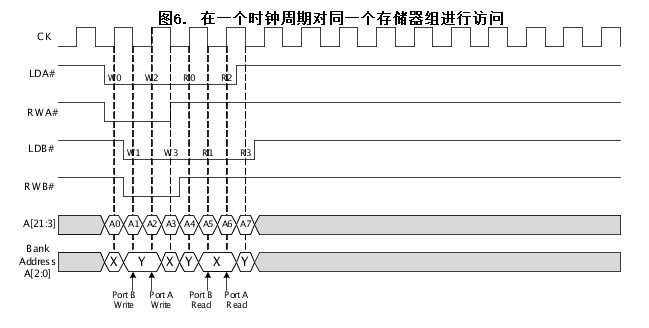
不过,如果第一次访问某一组是通过当前时钟周期的下降沿上端口B 进行的,并且第二次访问则是通过下一个时钟周期的上升沿上端口A 进行的,那么可以在一个时钟周期内再次对同一组进行访问。如图6所示,在进行写操作期间,端口B 和端口A 都可以在一个时钟周期内访问组Y。同样,在进行读操作期间,端口B 和端口A 可以在一个时钟周期内访问组X。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码