BP神经网络图像压缩算法乘累加单元的FPGA设计
(1)用小的随机数对每一层的权值和偏差初始化,以保证网络不被大的加权输入饱和,并进行以下参数的设定或初始化:期望误差最小值;最大循环次数;修正权值的学习速率;
(2)将原始图像分为4×4或8×8大小的块,选取其中一块的像素值作为训练样本接入到输入层,计算各层输出:

其中:f(・)为BP网络中各层的传输函数。
(3)计算网络输出与期望输出之间的误差,判断是否小于期望误差,是则训练结束,否则至下一步,其中反传误差的计算式为:
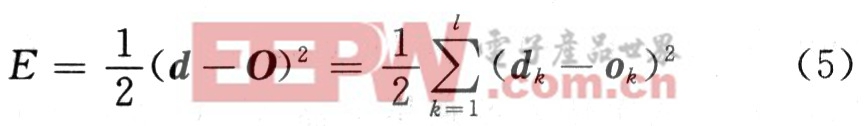
(4)计算各层误差反传信号;
(5)调整各层权值和阈值;
(6)检查是否对所有样本完成一次训练,是则返回步骤(2),否则至步骤(7);
(7)检查网络是否达到最大循环次数,是则训练结束,否则返回步骤(2)。
经过多次训练,最后找出最好的一组权值和阈值,组成三层前馈神经网络,用于该算法的FPGA设计。
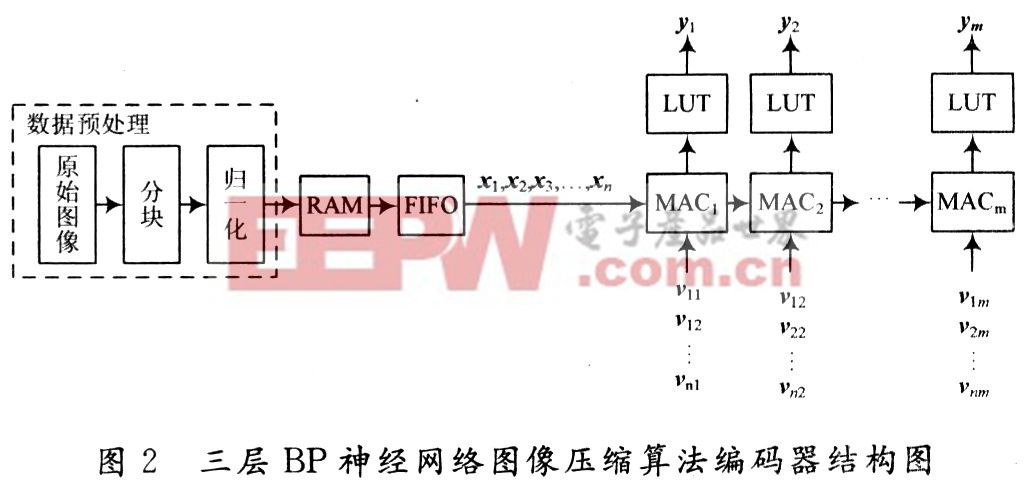
其中,在数据预处理部分,首先将原始图像分成n×n的小块,以每一小块为单位进行归一化。归一化的目的,主要有以下两点:
(1)BP网络的神经元均采用Sigmoid转移函数,变换后可防止因净输入的绝对值过大而使神经元输出饱和,继而使权值调整进入误差曲面的平坦区;
(2)Sigmoid转移函数的输出在-1~+1之间,作为信号的输出数据如不进行变换处理,势必使数值大的输出分量绝对误差大,数值小的输出分量绝对误差小。网络训练时只针对输出的总误差调整权值,其结果是在总误差中占份额小的输出分量相对误差较大,对输出量进行尺度变化后这个问题可迎刃而解。
归一化后得到以每小块的灰度值为列向量组成的待压缩矩阵,将该矩阵存储在RAM里,然后以每一列为单位发送给先人先出寄存器FIFO(First Input FirstOutput);由FIFO将向量x1,x2,…,xn以流水(pipe-line)方式依次传人各乘累加器MAC(Multiply-Accu-mulate),相乘累加求和后,送入LUT(Lookup Table)得到隐层相应的节点值,这里LUT是实现Sigmoid函数及其导函数的映射。
在整个电路的设计中,采用IP(Intellectual Prop-erty)核及VHDL代码相结合的设计方法,可重载IP软核,具有通用性好,便于移植等优点,但很多是收费的,比如说一个高性能流水线设计的MAC软核,所以基于成本考虑,使用VHDL语言完成MAC模块的设计,而RAM和FIFO模块则采用免费的可重载IP软核,使整个系统的设计达到最佳性价比。在压缩算法的实现中,乘累加单元是共同部分,也是编码和译码器FPGA实现的关键。
2.2 乘累加器MAC的流水线设计及其仿真
流水线设计是指将组合逻辑延时路径系统地分割,并在各个部分(分级)之间插人寄存器暂存中间数据的方法。流水线缩短了在一个时钟周期内信号通过的组合逻辑电路延时路径长度,从而提高时钟频率。对于同步电路,其速度指同步电路时钟的频率。同步时钟愈快,电路处理数据的时间间隔越短,电路在单位时间内处理的数据量就愈大,即电路的吞吐量就越大。理论而言,采用流水线技术能够提高同步电路的运行速度。MAC电路是实现BP神经网络的重要组成部分,在许多数字信号处理领域也有着广泛应用,比如数字解调器、数字滤波器和均衡器,所以如何提高MAC的效率和运算速度具有极高的使用价值。本方案采用的MAC设计以四输入为例。
四输入的MAC电路必须执行四次乘法操作和两次加法操作,以及最后的两次累加操作。如果按照非流水线设计,完成一次对输入的处理,需要这三步延迟时间的总和,这会降低一个高性能系统的效率。而采用流水线设计,则可以避免这种延迟,将MAC的操作安排的像一条装配线一样,也就是说,通过这种设计它可以使系统执行的时钟周期减小到流水线中最慢步骤所需的操作时间,而不是各步骤延迟时间之和,如图3所示。
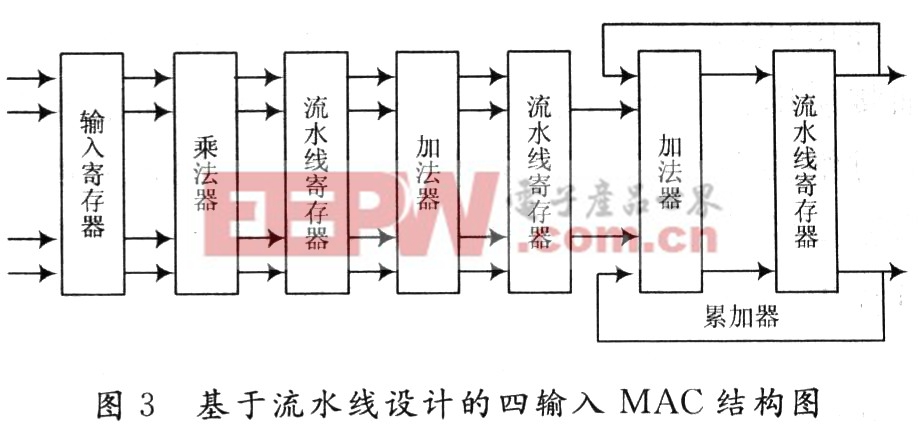
在第一个时钟边沿,第一对数据被存储在输入寄存器中。在第一个时钟周期,乘法器对第一对数据进行乘法运算,同时系统为下一对数据的输入作准备。在第二个时钟边沿,第一对数据的积存储在第一个流水线寄存器,且第二对数据已经进入输入寄存器。在第二个时钟周期,完成对第一对数据积的两次加法操作,而乘法器完成第二对数据的积运算,同时准备接收第三队数据。在第三个时钟边沿,这些数据分别存放在第二个流水线寄存器,第一个流水线寄存器,以及输入寄存器中。在第三个时钟周期,完成对第一对数据和之前数据的累加求和,对第二对数据的两次加法操作,对第一对数据的乘法运算,并准备接收第四对数据。在第四个始终边沿,累加器中的和将被更新。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码