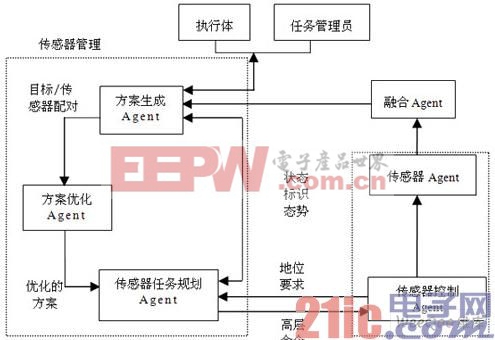
基于黑板的多Agent智能决策支持系统的Agent实现
如果τ(r)=φ(假设由一个动作作为结束),则不可能存在对的后继状态。在这种情况下,就说系统结束执行。同时,假设所有执行都最终会结束。形式上,环境Env是一个3元组Env=E,e0,τ>,其中E提供环境状态的集合,e0∈E是初始状态,τ是状态转移函数。把Agent的模型表示成一个函数,将一次执行(假设以环境状态为结束)映射到动作:
Ag:RE-AC
因此,Agent根据系统到当前为止的历史决定执行具体的动作。
系统是Agent和环境构成的对。任何系统都有与之相关的可能的执行集合:用R(Ag,Env)表示Agent在环境Env中的执行的集合。假设R(Ag,Env)只包含可以结束的执行,即执行r不存在可能的后继状态:τ(r)=φ(这里不考虑无限的执行)。形式上,序列:(e0,a0,el,al,e2,…)。表示Agent Ag在环境Envr=E,e0,τ>中的一次执行,如果:e0是Env的初始状态;a0=Ag(e0);对于u>0,那么:eu∈τ((e0,a0,…au一1))其中:au=Ag((e0,a0,…eu))
3.2 Agent的行为描述
构造Agent最主要的目的是为了决策,其决策过程是一个感知到动作的过程。把Agent的决策函数分解成感知函数see和动作函数action。Agent具有内部状态,设I是Agent的所有内部状态的集合,Per为(非空)的感知集合,Agent的决策过程基于这种信息,感知函数see实现从外部环境状态到感知的映射:see:E→Per。动作选择函数action定义为从内部状态到动作的映射:action:I→Ac。引入一个附加函数next,实现从内部状态和感知到内部状态的映射:next:IxPer→I。因此,Agent行为可描述为:Agent从某个初始内部状态i0开始,观察环境状态e,产生一个感知see(e),然后通过next函数更新Agent的内部状态,变成next(i0,see(e))。Agent通过action(next(i0,see(e)))选择动作。执行这个动作使Agent进入另一个循环,继续通过see感知外部世界,通过next更新状态,通过action选择动作执行。其过程如图2所示。

3.3 Agent的行为建模
Agent行为中的认知过程包括状态评估、决策制定、规划、学习等。Agent行为建模就是对认知处理所包含的几个认知过程进行建模。其中决策制定是核心过程。决策制定是从多个方法中选择具有最优效用的方法并执行的过程。可以用效用理论来衡量方案的优劣。
根据效用理论,假设有m个可选方案,在当前的状态下,采用的决策方案为Ai,产生的可能状态为Sj,每一状态的效用值是U(Sj),概率是Pj,则该决策的期望效用值为:
![]()
比较每个方案的不同期望效用,其中期望效用值最大的方案即为当前的最佳决策A,即:
![]()
例如,有3种可选择方法,2种状态的决策问题,状态空间用(ω1,ω2)表示,可选方案为A1,A2,A3,效用函数如表1所示。
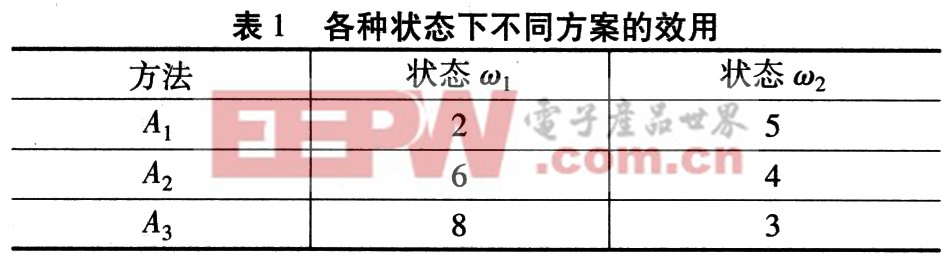
从表1可知,当前处于状态ω1时,A3是最好的选择;当前状态处于ω2时,A1是最优选择。当这两种状态分别以一定的概率p1,p2出现时,记p=p1,则p2=1-P。由式(1)和式(2)可得:

在概率不能确定情况下,根据式(3)判断概率的大致范围。如对Al最优的p应满足:5―3p≥4+2P,5―3P≥3+5p。则有p≤1/5。类似的可计算A2,A3最优对应的概率范围分别为1/5≤p≤1/3,p≥1/3。在能够判断决策范围的情况下,就可以据此对各方法进行分析,简化决策。当影响效用值的因素不止一个时,就需要采用适当的方法计算效用值,在各属性满足互斥条件,即各自产生的效用值互相独立时,可以采用加法的形式计算效用值。有时候,方法的选择需要体现灵活性和可变性,这时可以通过引入相关的随机变量建立随机效用模型来计算效用值,从而使决策结果更符合实际情况。
4 结语
采用的基于黑板的多Agent智能决策支持系统模型.每个Agent本身具有自治性,Agent之间通过黑板进行信息共享,利用黑板中的信息决定自身行为,协同完成复杂问题地求解。由于Agent自身具有不确定性,对多Agent系统需要解决Agent之间的有效协调,因此建立统一的协调机制,使Agent之间可以有效地相互协调工作,提高系统整体性能。实际应用中还有待于进一步完善。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码